Using Latent Dirichlet Allocation (LDA) for Topic Modeling in the Insurance Industry
Discover how LDA for topic modeling in the insurance industry uncovers insights from claims, customer feedback, and documents with smarter data analysis.
📚 Table of Contents
-
Introduction
-
What Is Latent Dirichlet Allocation (LDA)?
-
Why Topic Modeling Matters in Insurance
-
How LDA Works: A Simple Explanation
-
Applying LDA to Insurance Industry Data
-
Case Studies and Real-World Uses
-
Benefits of LDA for Insurance Companies
-
Challenges and Limitations
-
Best Practices for Using LDA in Insurance
-
Tools & Libraries for LDA Topic Modeling
-
LDA vs. Other Topic Modeling Techniques
-
Future of AI and NLP in Insurance
-
Conclusion
-
Resources and References
Understanding the Legal Profession in the UK: The Role of Lawyers
📝 Article Summary & Sample Sections
1. Introduction
The insurance industry handles massive amounts of unstructured data—from customer reviews to claims reports and emails. One powerful way to analyze all this text is by using LDA for topic modeling in the insurance industry. This technique helps insurers discover hidden themes in documents, saving time and improving customer understanding.
2. What Is Latent Dirichlet Allocation (LDA)?
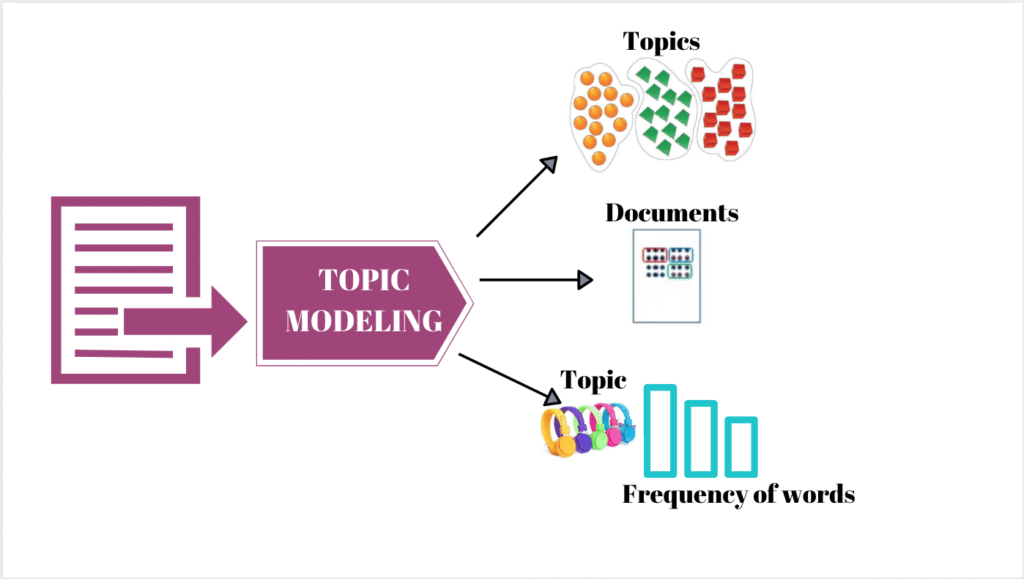
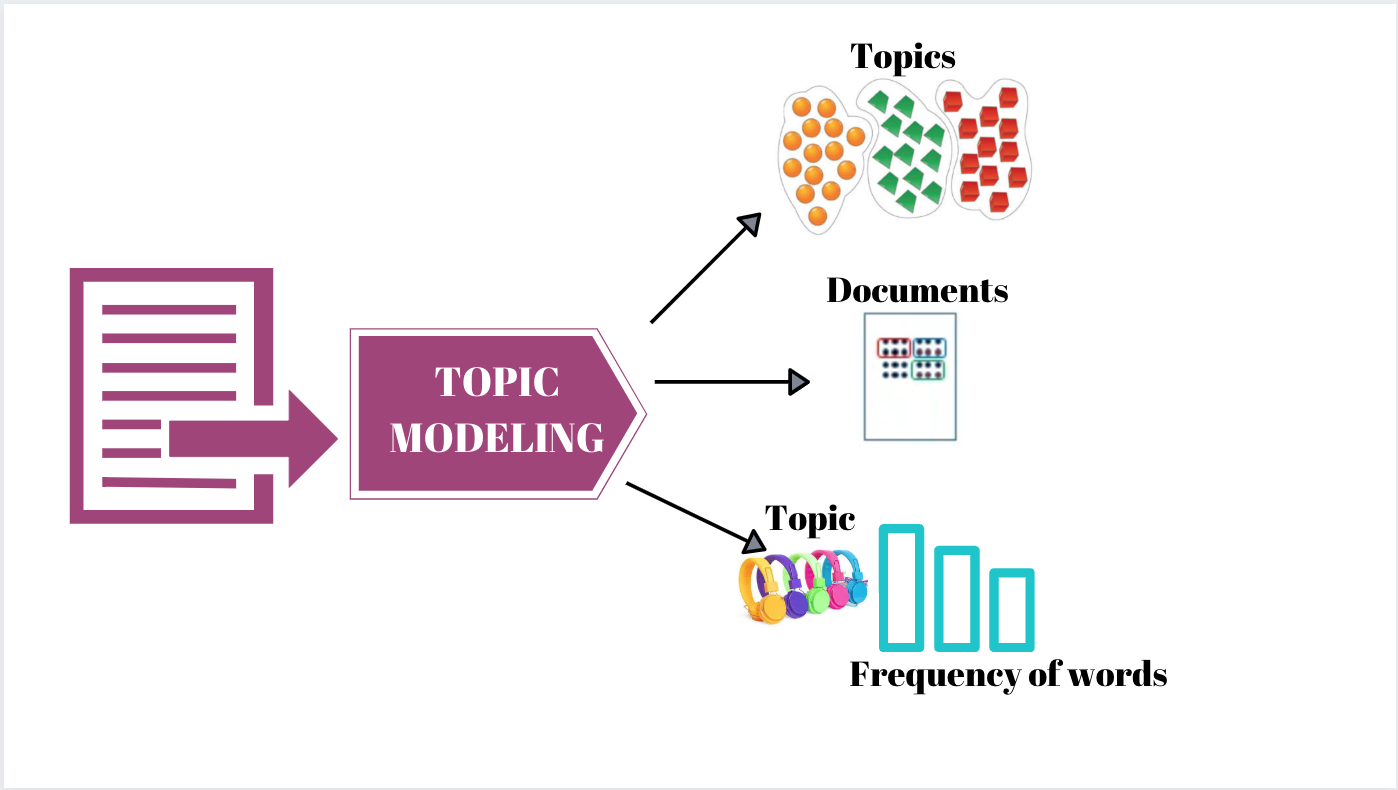
Latent Dirichlet Allocation (LDA) is a popular machine learning algorithm used for topic modeling, a method to automatically identify topics in large collections of text. LDA assumes each document is made up of a mix of topics, and each topic is a mix of words.
Imagine reading hundreds of insurance claims manually. LDA automates that—grouping documents by theme, like “car accidents,” “fraud,” or “storm damage.”
3. Why Topic Modeling Matters in Insurance
The insurance industry generates:
-
Thousands of claims reports
-
Tons of customer service emails
-
Policy documents
-
Underwriting notes
-
Social media feedback
LDA for topic modeling in the insurance industry allows insurers to:
-
Spot rising trends (like fraud patterns)
-
Understand customer pain points
-
Improve claim categorization
-
Identify common underwriting risks
4. How LDA Works: A Simple Explanation
At a basic level, LDA:
-
Takes a group of documents (e.g., insurance claims)
-
Looks at the words and guesses which ones tend to appear together
-
Groups these into “topics”
-
Assigns a mix of topics to each document
For example, if “collision,” “bumper,” and “accident” appear often, LDA might label that group as “auto insurance claims.”
5. Applying LDA to Insurance Industry Data
Here’s how insurers can apply LDA:
-
Step 1: Clean the data – remove stopwords, punctuation, etc.
-
Step 2: Tokenize – break text into words
-
Step 3: Vectorize – convert words to numbers (e.g., TF-IDF)
-
Step 4: Run LDA using tools like Gensim or Scikit-learn
-
Step 5: Analyze topics – check keywords under each topic
You might discover unexpected insights, like a rise in complaints about policy delays during certain months.
6. Case Studies and Real-World Uses
a) Claims Analysis
One insurance company used LDA to analyze 100,000 car accident claims. It discovered a spike in rear-end collisions in icy conditions—prompting a new winter policy warning.
b) Customer Support Text
LDA helped another firm group thousands of email complaints. The top themes? Delayed payments, misunderstood policy terms, and difficulty reaching agents.
c) Fraud Detection
By identifying strange topic patterns in claims, LDA flagged cases for deeper fraud investigation.
7. Benefits of LDA for Insurance Companies
-
Faster Document Classification
-
Improved Risk Understanding
-
Automated Insights from Text
-
Enhanced Customer Experience
-
Support for Product Development
LDA for topic modeling in the insurance industry isn’t just technical—it helps businesses grow smarter.
8. Challenges and Limitations
-
Requires clean, structured data
-
Hard to name topics automatically
-
Needs tuning (number of topics, etc.)
-
Doesn’t capture word meaning (semantics) deeply
-
Sometimes overlaps similar topics
Despite this, LDA is still widely used due to its simplicity and interpretability.
9. Best Practices for Using LDA in Insurance
-
Start with a small dataset to test
-
Use domain experts to label topics
-
Combine with sentiment analysis for deeper insight
-
Visualize using tools like pyLDAvis
-
Preprocess carefully: clean text = better topics
10. Tools & Libraries for LDA Topic Modeling
Popular tools include:
-
Gensim (Python) – widely used for LDA modeling
-
Scikit-learn – general machine learning, with LDA options
-
MALLET – powerful but requires Java
-
pyLDAvis – great for visualizing topics
-
spaCy – for text cleaning and preprocessing
11. LDA vs. Other Topic Modeling Techniques
| Technique | Strength | Weakness |
|---|---|---|
| LDA | Easy to use, explainable | Not always deep or accurate |
| NMF | Better with sparse data | Less interpretable |
| BERTopic | Uses BERT + clustering | Needs more compute |
| LDA2Vec | Combines word vectors + LDA | Complex to implement |
LDA is still a strong baseline tool, especially in traditional industries like insurance.
12. Future of AI and NLP in Insurance
As AI gets better at understanding language, future topic models will:
-
Detect emotion and intent
-
Adapt in real time
-
Merge voice/text data
-
Feed directly into business decisions
Still, LDA will remain useful for quick, explainable topic insights in insurance workflows.
13. Conclusion
Using LDA for topic modeling in the insurance industry helps unlock hidden patterns in messy text data. From claims to customer feedback, LDA gives insurers a fast, data-driven way to find what’s really going on. Whether it’s spotting fraud or improving service, topic modeling is now a must-have tool in modern insurance analytics.

